Query by Phrase
Query by Phrase
Project Overview
Sound and speech signal processing have been featured for a long time in our teams as well as CG, CV and content processing Armi6.5. Especially an automatic lip-sync animation generation from pre-scored voice has been a very essential topic for a long time. Recently, music retrieval from big data is challenged using query by music sentence played by any instrument windows 95 다운로드.
In a speech processing, there are two main topics “lip-sync” and “voice conversion”. Lip-sync in which mouth shape is automatically generated with synchronization to spoken voice has been challenged since 1987 to produce an innovative system “AniFace” in which huge prior knowledge of spoken language is taken advantage and time sequential feature is modeled with Hidden Markov Model(HMM) 매직 원 1.0 다운로드. On the other hand, a new approach for automatic mouth shape generation directly from voice signal or sentence without any database or speech recognition result is also challenging topic 6 downloads of descendants of the Sun. Many proposal of mouth opening control based on a utterance speed and elimination of discontinuity of mouth motion using free-form curve have been given until now 맥북 icloud 사진 다운로드.
In a voice conversion research, a trial to convert a personal characteristic in a voice signal from one to other by controlling pitch, power and utterance speed based on Straight parameter conversion fastboot 드라이버 다운로드. Currently by a linear blending and adjustment of each blending weight of voice parameters from several people, we succeeded to produce a new voice by keeping personal characteristics of a target person 갓세븐 다운로드. At the same time, a criterion to decide the quantitative similarity measurement between two voices has been proposed.
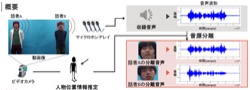
In a sound signal processing, sound source separation is tried by micro phone array (HARK) and final goal of this research is to separate a target person’s voice focused in a surveillance video camera and to play back isolated voice clearly and naturally 여장산맥.
In a music processing, searching a composition and a location of sentence played by a single instrument in a music big data is realized by Non-negative Matrix Factorization (NMF) with non-parametric baysien model 청량음악. A new approach in which a different instrument, playing speed and key are allowed is tried recently.
Related Images
Related Themes