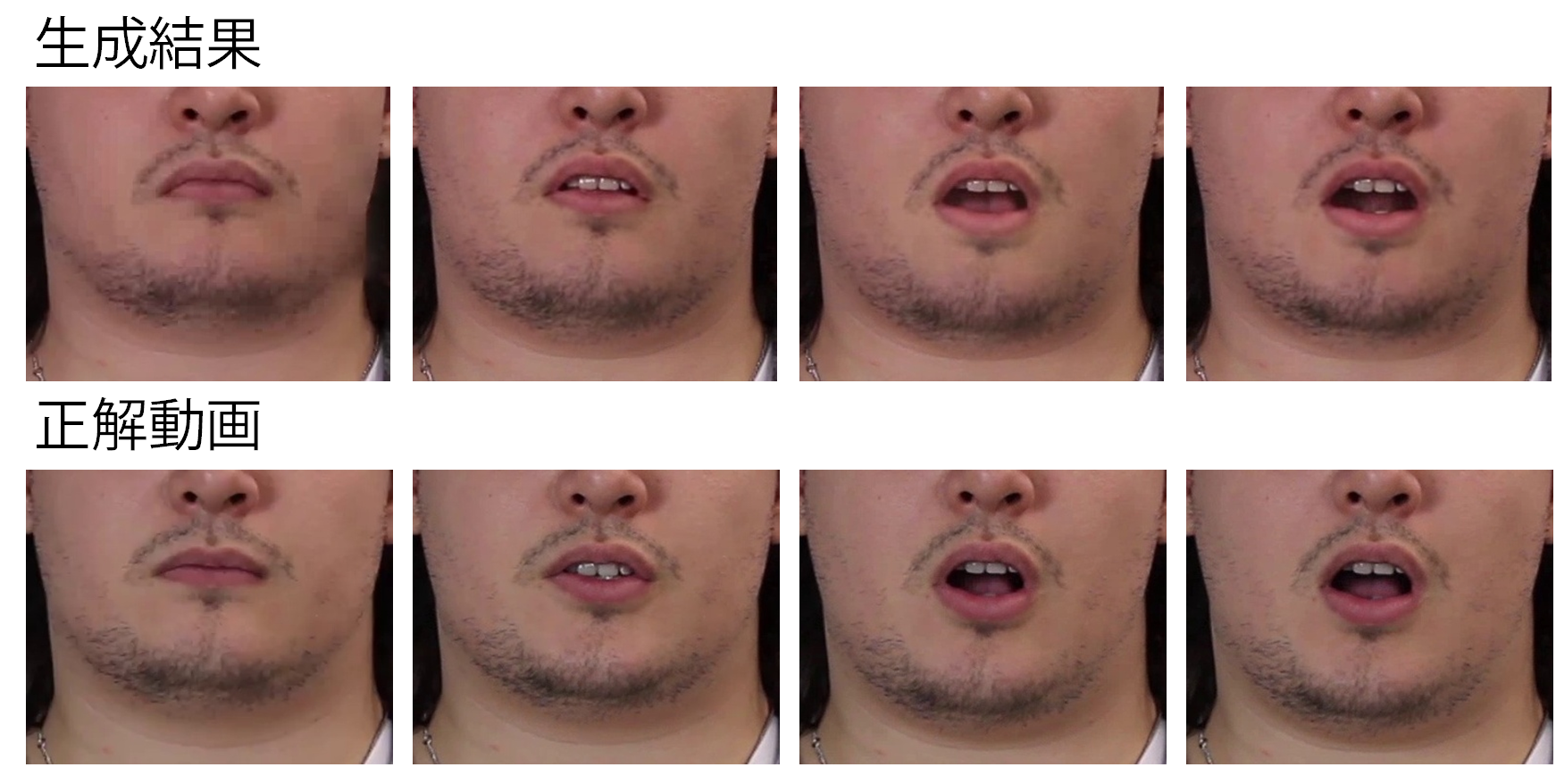
古川翔一, 加藤卓哉, サフキンパーベル, 森島繁生
顔の発話動作と音声とを同期させた映像を生成する手法の提案
フォーラム顔学2016
cx_oracle 다운로드
近年,外国語の映像コンテンツの増加に伴い,吹替処理の需要が一層高まっている.しかし,従来の吹替処理では口の動きと音声を完全に一致させることは難しい.Ezzatら[1]は入力した音声からそれに合う口画像を生成して発話映像を作成した.しかし,Ezzatら[1]の手法では音素情報を用いるため,他の言語に適用する際はその都度モデルを構成し直さなければならない.そこで本研究では,吹替対象映像(以下,俳優動画)と声優が吹替をしている様子を撮影した映像(以下,声優動画)の二つを入力し,声優と同じタイミングで同じ口形状が現れるように俳優動画のフレームを並べ替えることでリップシンク映像を作成する.本手法は音素情報を用いないので多言語に適用可能である.また本手法のフレームワークは二次元アニメなどの顔形状の取得が難しい映像にも適用できる.
강변북로체 다운로드 천년바위 Unforgettable 좀비고