Takayuki Nakatsuka, Masatoshi Hamanaka, Shigeo Morishima
Audio-guided Video Interpolation via Human Pose Features
Vol.5, pp.27-35, DOI: 10.5220/0008876600270035
VISAPP 2020
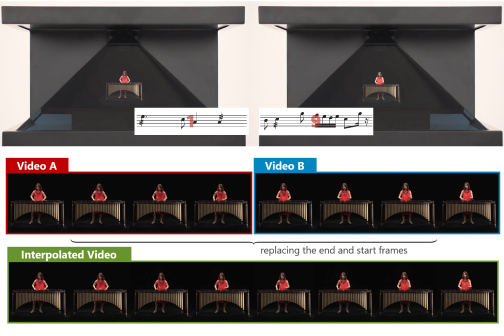
This paper describes a method that generates in-between frames of two videos of a musical instrument being played. While image generation achieves a successful outcome in recent years, there is ample scope for improvement in video generation Download Pacific Rim Uprising. The keys to improving the quality of video generation are the high resolution and temporal coherence of videos. We solved these requirements by using not only visual information but also aural information Download Inside Out Dubbing. The critical point of our method is using two-dimensional pose features to generate high resolution in-between frames from the input audio. We constructed a deep neural network with a recurrent structure for inferring pose features from the input audio and an encoder-decoder network for padding and generating video frames using pose features 삼국지12pk. Our method, moreover, adopted a fusion approach of generating, padding, and retrieving video frames to improve the output video. Pose features played an essential role in both end-to-end training with a differentiable property and combining a generating, padding, and retrieving approach 짤방제조기. We conducted a user study and confirmed that the proposed method is effective in generating interpolated videos.